2026-07-07
Assay cross-model Phase M sweep confirms seal defense can discriminate tool-chaining and chain-of-thought attacks — attack classes that read as background noise in single-model evaluation
The evaluation framework's Phase M attack battery — tool-chaining (STAC), hierarchical chain-of-thought (HCOT), and cross-modal injection — was re-evaluated across multiple model architectures with seal-epd-llm inline, and the numbers tell a different story from the single-model read. Where Phase M registered zero discrimination (the defense could not distinguish tool-chaining attacks from benign tool calls), the cross-model sweep finds measurable discrimination across all three attack classes: 80.0 for STAC and HCOT, 60.0 for cross-modal, each with zero false positives (FPR=0%). The result is not that seal-epd-llm learned to see something it could not see before — it is that coverage is architecture-dependent: an attack class that looks like noise on one model reveals structure under the defense on another. The evaluation framework now treats this as a first-class dimension: a risk-gated defense evaluation that sweeps not only across models but across attack-structural classes, so a coverage gap on one architecture does not masquerade as a fundamental limitation of the defense approach.
2026-07-02
Assay benchmark engine goes defense-agnostic — LLM Guard benchmarked as first third-party defense alongside seal
Assay's benchmark runner now treats defenses as a pluggable dimension rather than a hardcoded pairing. The engine accepts a `--defenses` flag that applies any middleware uniformly across all probe engines, and the defense registry is extensible by design — adding a new defender means implementing one interface and declaring it in the map. LLM Guard (Protect AI) has been benchmarked as the first third-party defense alongside seal across all three target models (qwen3:8b, qwen2.5:14b, llama3.1:8b), producing cross-model LLM Guard coverage spanning 126 total benchmark runs. The runner is no longer tied to any single defense ecosystem; any middleware can now be measured against the same probe battery, on the same models, on the same terms, so the question shifts from 'does seal work?' to 'how do the available defenses compare on a common instrument.'
2026-06-30
Assay ships cross-model benchmark pipeline — 7 engines, 3 model architectures, published comparative benchmarks
Assay's evaluation pipeline is no longer a one-off instrument. All seven engines now run end-to-end as a systematic cross-model benchmark that has been validated across three distinct model architectures (qwen3:8b, qwen2.5:14b, llama3.1:8b) with published comparative results. The pipeline is a reusable evaluation capability: any model, open- or closed-weight, can be benchmarked across the full discrimination battery as a recurring discipline rather than a custom effort — making cross-model AI security evaluation routine. The next horizon (Phase I) extends the runner to be defense-agnostic, so any middleware can be benchmarked, not just seal, with LLM Guard as the first third-party defense candidate.
2026-06-27
Assay verifies seal-epd-llm defense is model-independent — cross-model validation confirms 93.3% injection-blocking across architectures
An independent cross-model validation of seal-epd-llm injection defenses, run via Assay on qwen2.5:14b, reproduced the identical 93.3% injection-blocking rate measured on the original target model — with the same three bypasses (deepinception, past-tense, crescendo-fictional-frame) in both cases. The result is the first published confirmation that seal-epd-llm's effectiveness is model-independent: the defense targets probe-level injection patterns, not model-level quirks, so evaluation results transfer across architectures and the technique can be trusted as a property of the defense itself. Phase G extends the benchmark to three or more models with full harmbench replication, establishing a publishable cross-model AI security benchmark.
2026-06-21
New project — DECK: when the visualization is the scan
DECK (Digital Echo Chamber Kaleidoscope) is a new R&D project — a 3D cosmos you fly through where reconnaissance renders at the speed information arrives. Point it at a domain and that target's full vertical footprint (domain to subdomain to IP to prefix to ASN, plus nameservers and mail) materializes live as a starfield, each node igniting the millisecond its passive-OSINT probe returns. The central idea is collapsing the gap between tool and output: there is no scan-then-draw step, so probe latency itself becomes the choreography — fast data fills the space first, slow data drifts in after. It is a different axis of internet cartography from the familiar maps (Opte, Shodan, crt.sh), which each render one frozen layer of the entire internet; DECK reconstructs a single target's complete footprint, live, on demand, with zero API keys. The metaphor carries the legibility: autonomous systems become suns, prefixes planets, hosts moons, and BGP links gravitational lanes, so abstract infrastructure turns into something you navigate by eye. A 'home base' mode turns the same engine inward as a defensive instrument — it maps your own machine outward in concentric shells and treats your normal BGP neighborhood as a still-water baseline, so any live connection leaving for somewhere outside that ring reads as a wave hitting a buoy: anomalous by construction. The lineage is Gibson's Neuromancer, where the deck is the thing you jack into to see cyberspace as navigable space.
2026-06-19
Seal's provenance protocol goes language-agnostic
The Verified Prompt Envelope — Seal's Ed25519-signed authorization layer — is no longer a Python-only idea. The envelope is defined by its wire format and signature scheme rather than any one runtime, so the central claim becomes concrete: prompt provenance is a protocol, not a library feature. Native implementations now exist in Rust, Go, and TypeScript alongside Python, which means an agent written in any of them can mint, carry, and verify the same authorization. The trust boundary follows the data across every tier of a heterogeneous stack instead of stopping at whatever language the defense happened to be born in. Provenance that only works in one runtime isn't a security primitive; provenance that survives the language boundary is.
2026-06-17
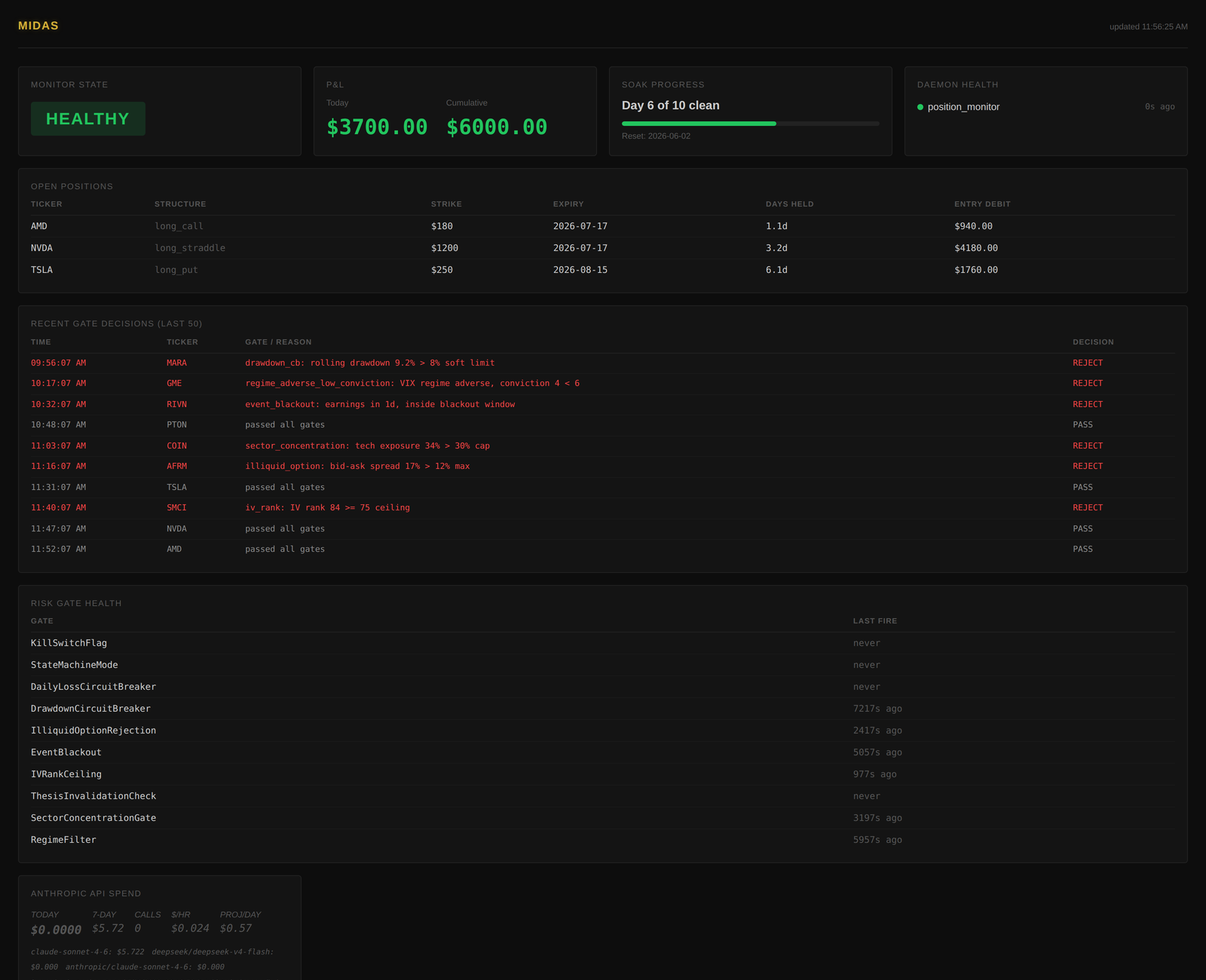
Midas: designing a decision engine to survive being wrong
Most automated decision systems are built to be right. Midas is built to survive being wrong — because in capital allocation a single oversized mistake ends the game, while being right is merely pleasant. The architecture encodes that asymmetry directly: candidate theses, formed by reading primary-source filings, must clear a layered gauntlet of independent risk gates before anything acts, and 'no decision' is the default outcome rather than a failure mode. The design thesis is that the gate layer — not the prediction — is the product: a system that does nothing unless conviction and bounded downside both clear is the only kind worth letting near real capital.
2026-06-17
Grommet concludes — three impossibility results for extraction-resistant sequencing
Grommet is an adversarial mechanism-design investigation into extraction-resistant transaction sequencing (MEV). Its terminal result is a formal impossibility: a content-blind safety mechanism cannot simultaneously bound attacker extraction and pass legitimate throughput under market stress — the two goals trade off hard. The deliverable is the constraint framework itself: it turns 'is it MEV-resistant?' from marketing copy into a falsifiable question, and ships an audit checklist any protocol making that claim should have to answer. The same safety principle has a constructive flip side — a minting rule for an engine-backed currency, the one regime where the impossibility does not bind.
2026-06-10
Seal grows to a three-axis trust layer, with Assay as the evaluator
Seal now coordinates all three agent-security axes — prompt provenance (Ed25519-signed authorization), injection detection (EPD linguistic boundary enforcement), and signed memory-trust — into a single unified defense plane. Each axis is independently effective, but their power is architectural: injection cannot rewrite provenance, memory-trust cannot be forged without the signing key, and no single-axis failure compromises the others. The three axes function as a coordinated defense plane, not three separate tools bolted together. Assay, the paired evaluator, scores a target across all three and measures the lift the defense actually adds.
2026-05-30
Seal: cryptographic provenance for agent prompts
Shipped the Verified Prompt Envelope — Ed25519-signed authorization that lets an agent reject unauthorized instructions by construction, turning prompt-injection defense from guesswork into key management.